The Real Result Isn't 67% — It's That the Data Was Messy
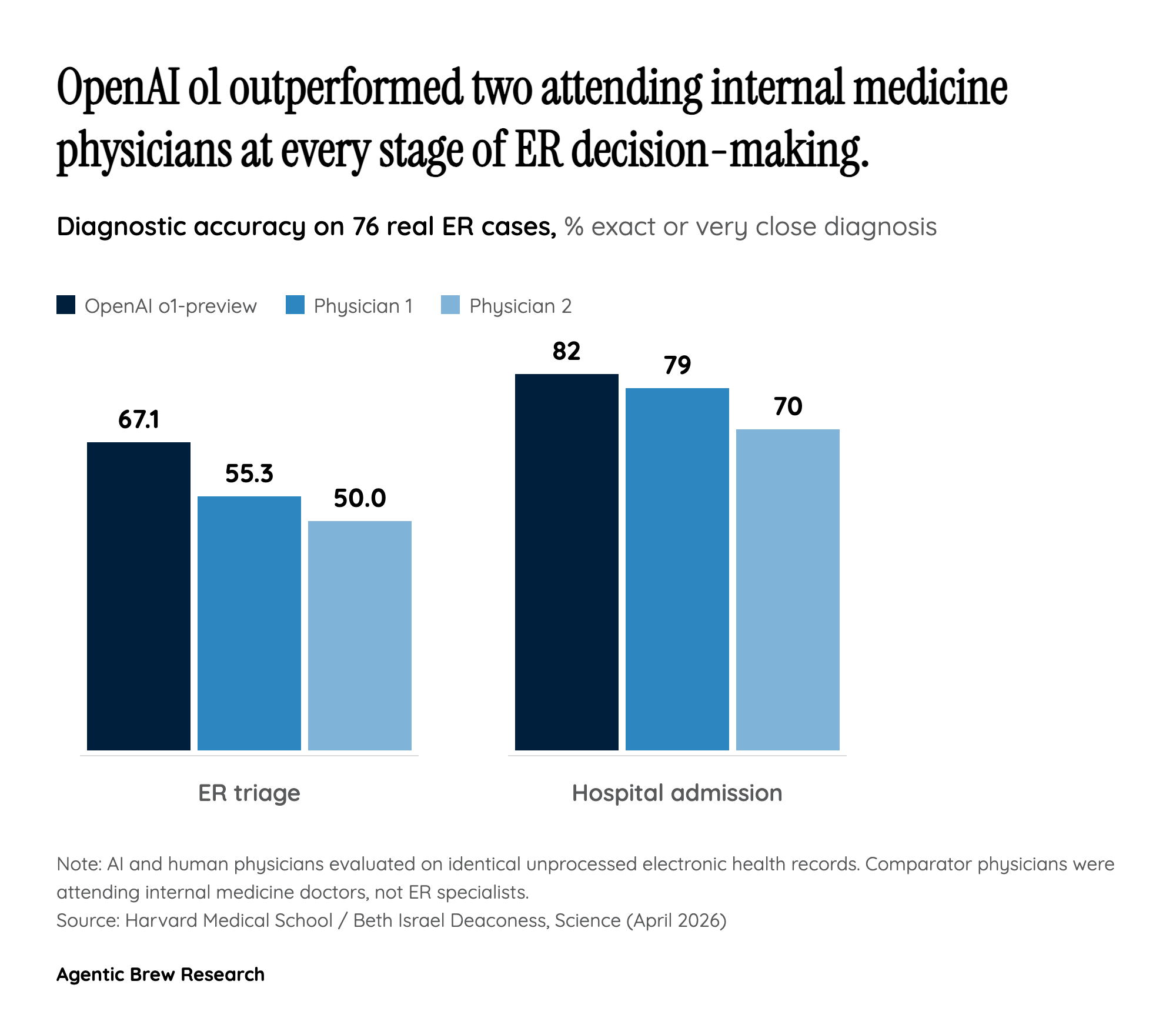
The headline number — 67.1% diagnostic accuracy versus 55.3% and 50.0% for human attendings — is striking, but the methodological choice underneath it is the more consequential finding. Unlike previous medical AI evaluations, the Harvard team did not curate, summarize, or vignette-ify the cases. Each ER patient was handed to o1-preview exactly as the chart appeared in the electronic health record: vital signs, intake nurse notes, free-text fragments, and all. That is the closest thing the literature has produced to an in-the-wild physician comparison.
The second mechanical pillar is the model itself. o1-preview was OpenAI's first 'step-by-step reasoning' system, and the authors attribute the leap over GPT-4o — its non-reasoning predecessor — to that architectural change. On a separate 70-case NEJM head-to-head, o1-series scored ~89% exact-or-very-close versus ~73% for GPT-4. In other words, the jump in real ER triage tracks the jump on hard published cases, suggesting it isn't an artifact of the 76-case sample. The story is: a reasoning model, fed raw clinical text, beat physicians who had access to the same record. That is a different claim than 'AI passes the USMLE,' which the field has heard for two years.


