
The Hallucination Math That Doesn't Quite Add Up
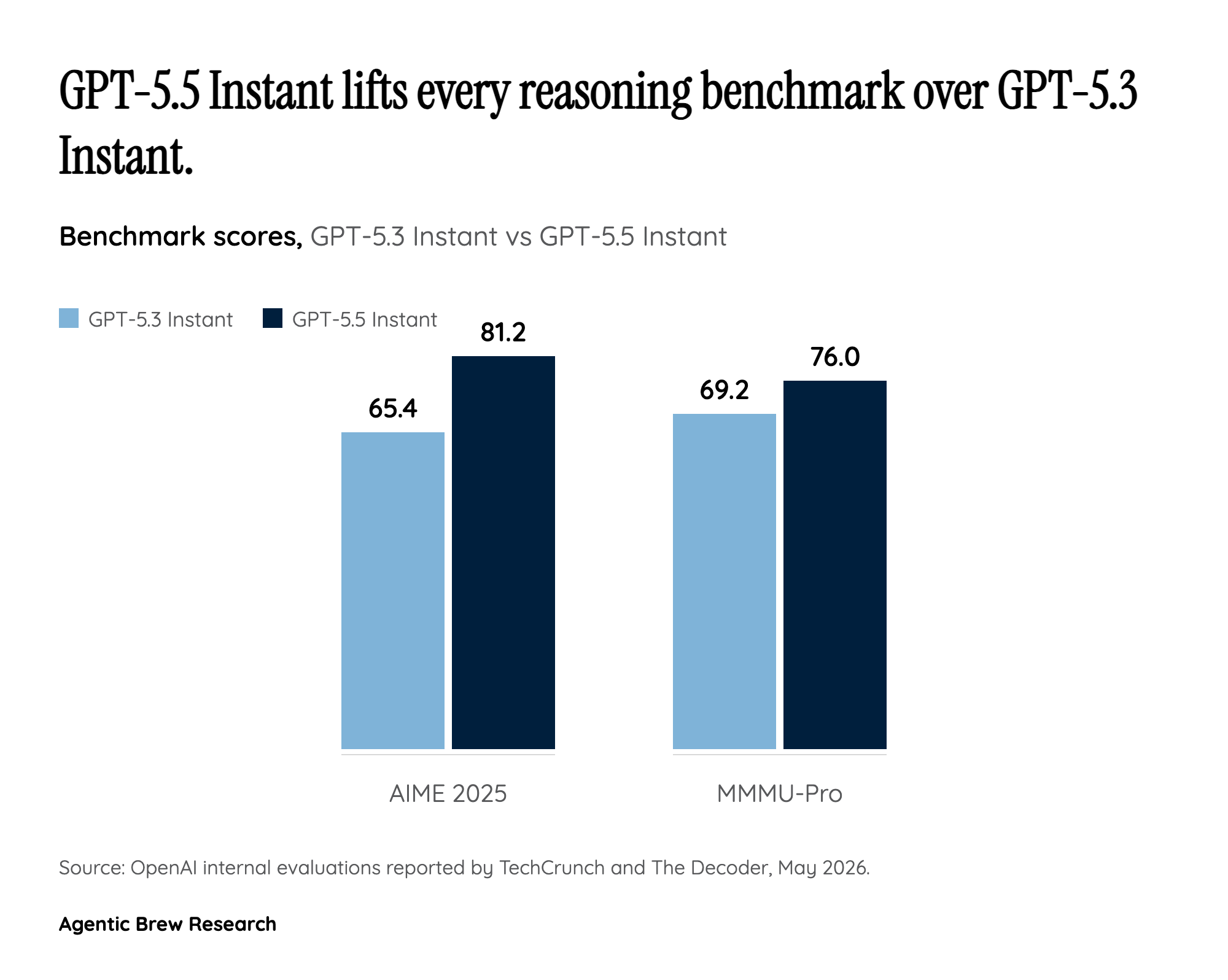
OpenAI's headline number for GPT-5.5 Instant is a 52.5% reduction in hallucinated claims on high-stakes medicine, law and finance prompts, plus a 37.3% drop on user-flagged challenging conversations versus GPT-5.3 Instant. Benchmark gains follow the same shape: AIME 2025 jumps from 65.4 to 81.2, and MMMU-Pro climbs from 69.2 to 76. Read in isolation, that looks like a clear answer to the most consistent criticism of prior default models.
The complication is the independent picture. Artificial Analysis still measures an 86% hallucination rate for GPT-5.5 (xhigh) on its AA-Omniscience benchmark, well above Claude Opus 4.7 (max) at 36%, even as it ranks GPT-5.5 first overall on the Intelligence Index by three points, breaking a previously tight three-way race with Anthropic and Google. The internal-versus-external gap is exactly what Arena evaluator Peter Gostev flagged: where GPT-5.5 Instant lands in public Arena tests will indicate whether OpenAI's accuracy gains generalize beyond OpenAI's own evaluations. Reddit users in r/accelerate report it is the first Instant model that says 'I don't know' in their hallucination tests, suggesting calibration improved on common prompts. Major AI explainer channels on YouTube quickly produced high-traction walkthroughs framing it as OpenAI's 'best model' yet, with focus on the benchmark deltas and Codex Agents integration — evidence that the launch landed loudly with the creator and developer audience even before independent evaluators weighed in. The honest read for now: large gains on the prompts OpenAI optimized for, much smaller margins outside them.


