The 1:1 Bet — Why Agents Pull Compute Back to the CPU
The headline number is the doubled TAM, but the load-bearing claim sits underneath it: AMD now believes the CPU-to-GPU ratio inside AI data centers is sliding from the historical 1:8 toward 1:1. Lisa Su has gone further on stage, telling investors that with enough agents per server, 'you could have more CPUs than GPUs.' That is not a marketing flourish; it is a specific architectural read of what an agent workload actually does. A pure LLM training run is GPU-bound — backpropagation through trillions of parameters is exactly what tensor cores are built for. An agent is something else: it is a loop of small inferences interleaved with tool calls, web fetches, Python execution, retrieval against a vector store, JSON parsing, and policy decisions. Each of those steps is a general-purpose CPU job, not a matmul.
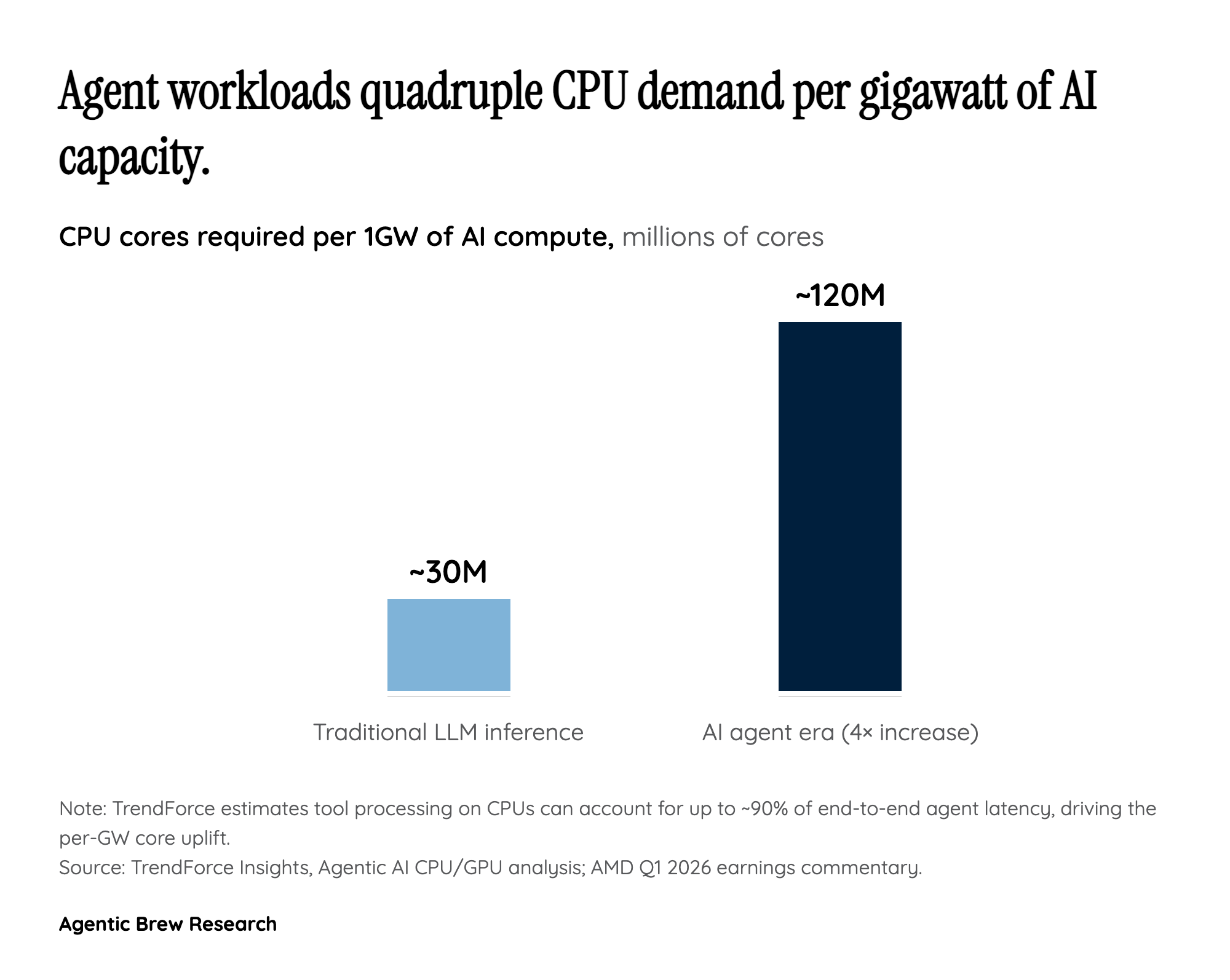
The quantitative version of this shift comes from TrendForce, which estimates that one gigawatt of agent-era infrastructure consumes roughly 120 million CPU cores — about a fourfold jump versus a comparable LLM-inference deployment. Their analysis frames it bluntly: tool processing on CPUs can account for as much as 90% of end-to-end agent latency, which means the CPU is no longer a passive scheduler bolted next to the accelerator. It is the bottleneck. Once that becomes the design constraint, the rational move for hyperscalers is to specify nodes with more — and more capable — CPU silicon per accelerator, not less. The TAM doubling is the financial expression of that design pivot. AMD is essentially saying: agents are not a side workload that runs on the same boxes as training; they are a different shape of workload that pays a CPU premium, and the industry's collective five-year capex needs to reflect that.