The Harvey 6x: Long-Horizon Agents Were Memory-Bound, Not Capability-Bound
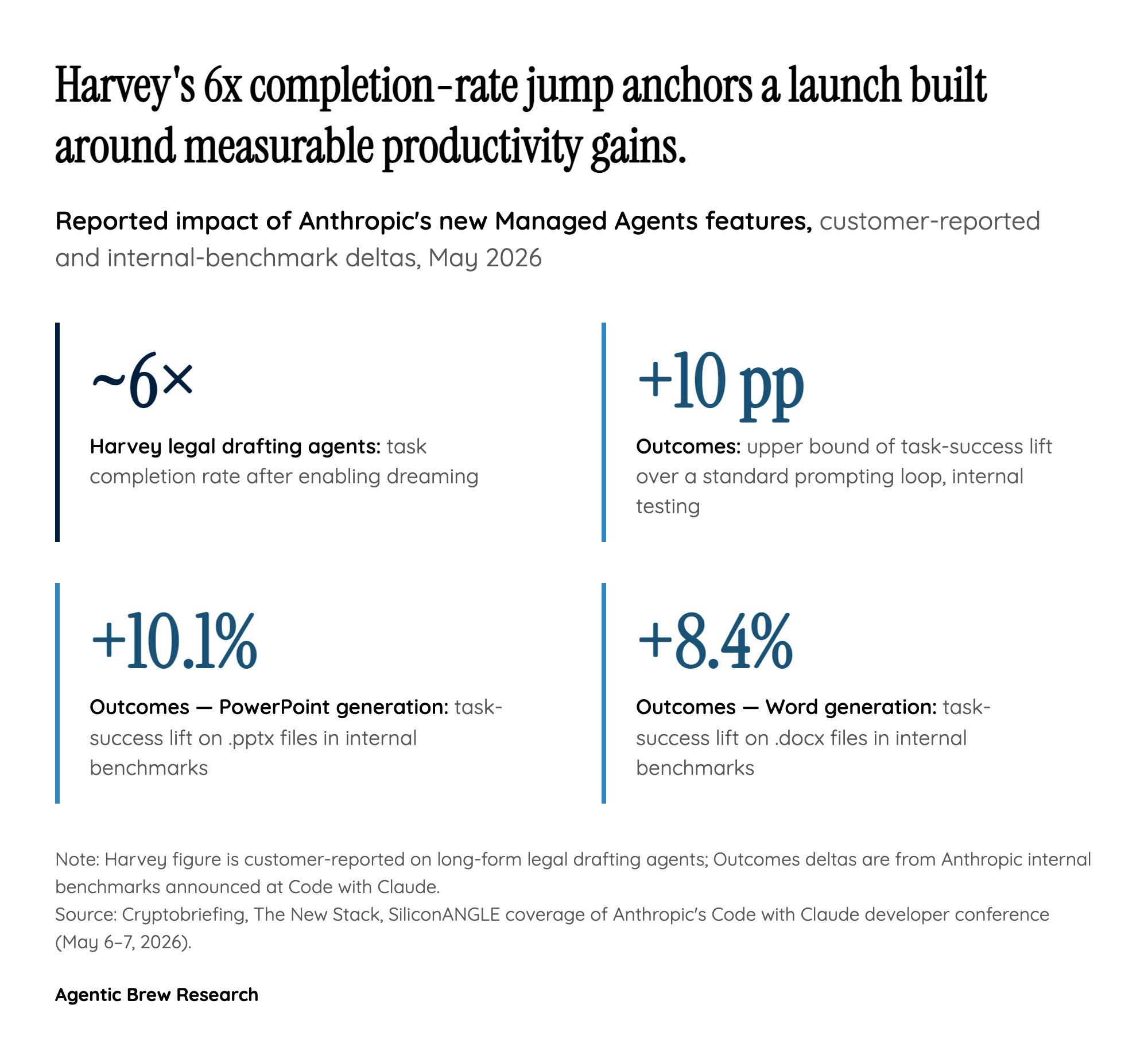
The single most consequential datapoint from the launch is not architectural but empirical. Harvey, building legal drafting agents on Managed Agents, saw completion rates climb roughly six-fold once dreaming was enabled. That is not the kind of delta you get from a smarter base model or a better prompt; it is the delta you get when a system that was previously failing for structural reasons stops failing. The implication is uncomfortable for the dominant 'just scale the model' narrative: for long-form, multi-session work, the bottleneck on agent quality has been context-window management, not raw reasoning.
If that read holds, dreaming is less a feature than a competitive moat. Anthropic is effectively saying that the path to useful production agents runs through memory curation, not just larger context windows or cheaper tokens. Harvey's result lines up with the smaller but directionally consistent gains reported for Outcomes, the sibling feature announced at the same event, which improved task success by up to 10 percentage points in internal testing and lifted .docx generation by 8.4% and .pptx by 10.1%. Taken together, the launch reframes agentic AI quality as a memory-engineering problem, and Anthropic is shipping the first credible API-level answer.


