
The mechanism: exploiting the speed gap between text generation and speech
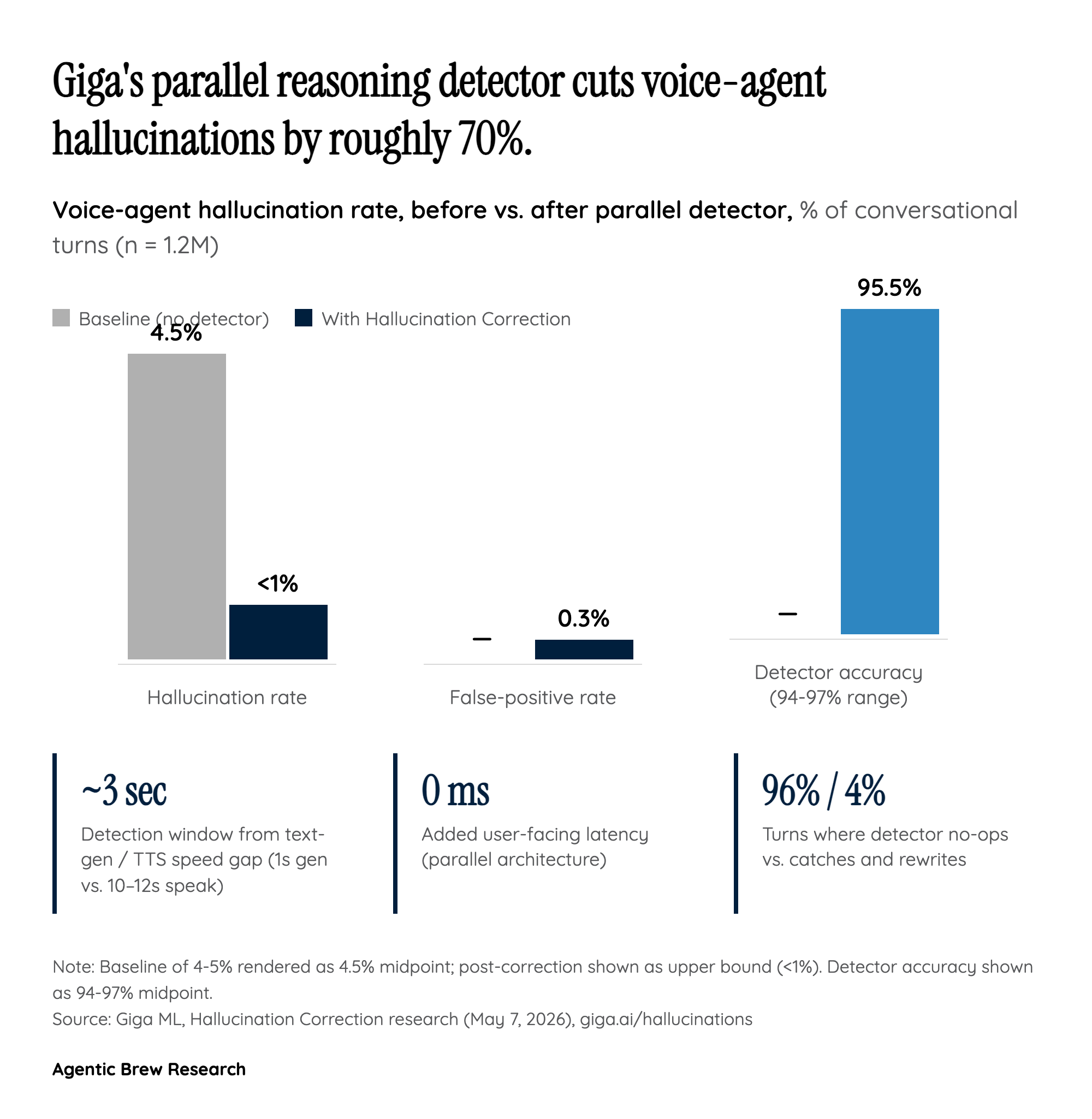
The clever insight in Giga's Hallucination Correction system is structural rather than purely model-based. LLMs generate text far faster than voice models can speak it: a roughly 30-word response is generated in about 1 second but takes 10-12 seconds to actually play through TTS. That mismatch is normally just dead time, but Giga turned it into a budget — leaving roughly 3 seconds in which a parallel reasoning model can evaluate the chunk and intercept it before the user hears anything.
The architecture is two LLMs running concurrently: the primary generator streams a response, while a reasoning detector reads the same chunk against the system prompt, retrieved context, and prior turns to flag instruction contradictions, context contradictions, and fabrications. Because the detector runs in parallel rather than in series, there is zero added user-facing latency. The reported numbers — hallucination rate dropping from a 4-5% baseline to under 1% across 1.2 million conversational turns, detector accuracy of 94-97% across hallucination types, and a false-positive rate below 0.3% — only matter because the design lets you run an expensive reasoning check without the user noticing.
A second non-obvious detail: when the detector catches an error, the corrective hint must be dropped from context after the chunk is fixed. Otherwise the primary model learns from the visible patch and starts hedging on every subsequent answer. The fix has to leave no trace, or the cure deforms the model.


