
Islands, Not Armies: How Decoupling Rewrites the Training Contract
Classical large-model training is a kind of military formation — every accelerator marches in lockstep, exchanging gradients at every step, and a single stumble halts the whole line. Decoupled DiLoCo replaces that formation with a loose federation. Training is split into 'islands' of compute, each doing many local optimization steps on its own, and then exchanging only compact outer updates asynchronously between islands. The mathematical ancestor is federated averaging; the engineering ancestor is Google's Pathways, which is what lets those asynchronous flows cross regions without the whole system stalling on the slowest link.
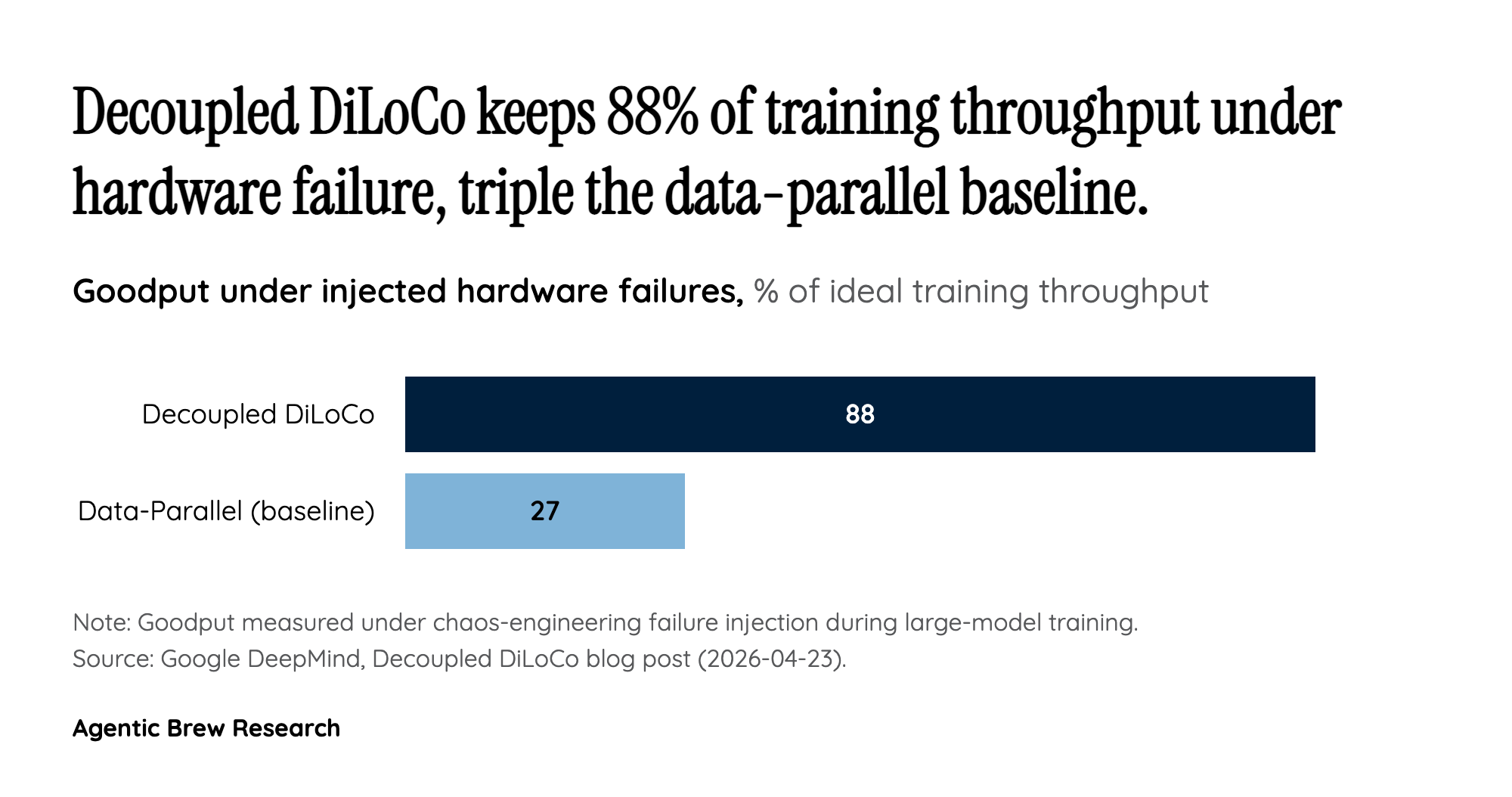
The consequence is a different failure contract. In Arthur Douillard's phrasing, 'the blast radius of a chip failing is limited to its island of compute.' When DeepMind's team injected failures chaos-engineering-style, the remaining islands kept learning and the downed ones were reintegrated when they came back — yielding 88% goodput versus 27% for data-parallel under the same conditions. That is not a small optimization; it reclassifies hardware failure from a run-ending event to a routine operational blip, which is precisely the property a geographically distributed training run needs if it is ever going to be practical.


