
Wall Street's Headline-Reading Problem: Why SanDisk Lost 14% Over an Algorithm That Doesn't Touch NAND
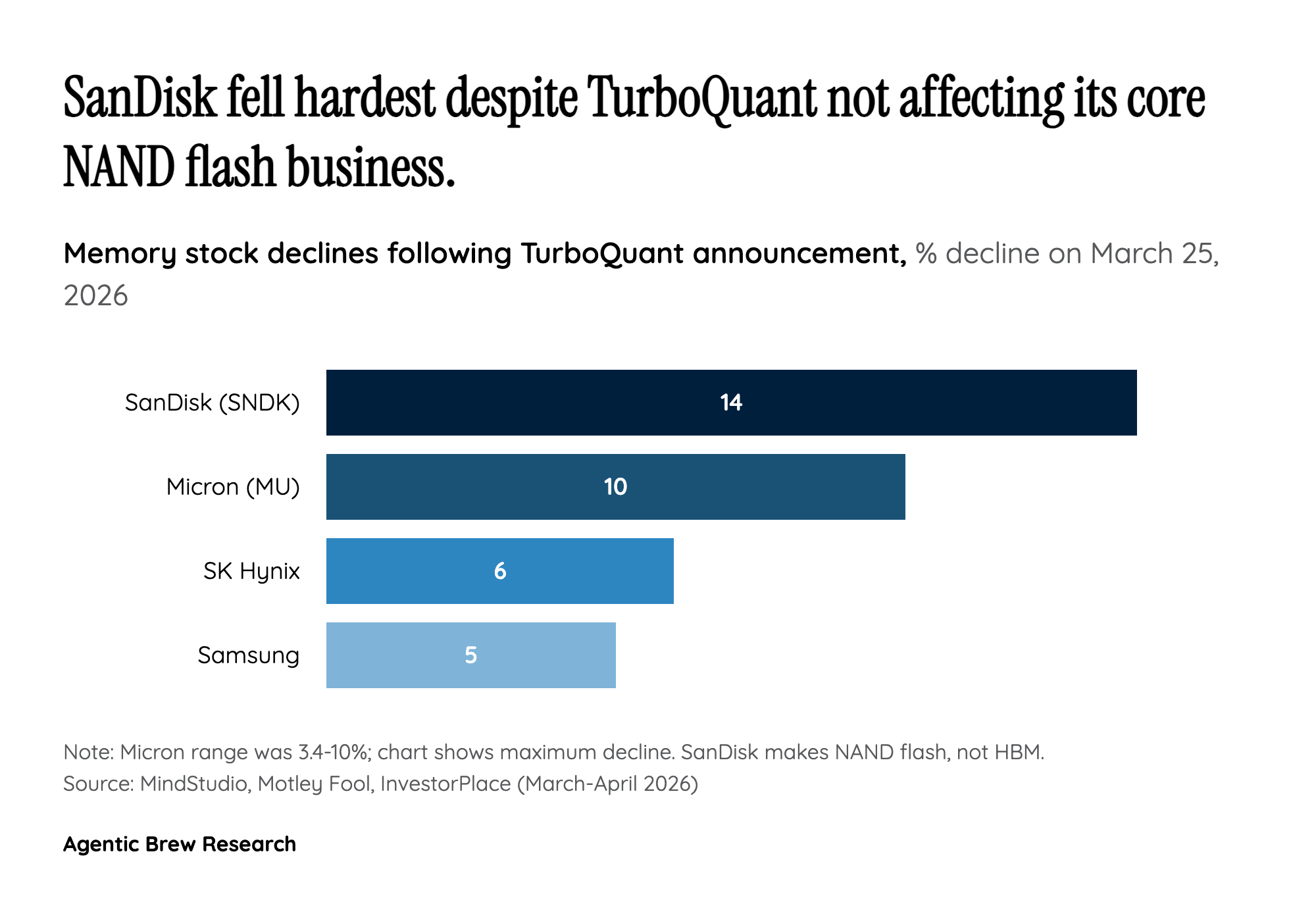
The most telling detail in the TurboQuant sell-off is not the stocks that fell, but the one that fell the most. SanDisk (SNDK) dropped 14% — more than double SK Hynix's decline — despite the fact that TurboQuant targets HBM (High Bandwidth Memory) used in GPU caches, a technology entirely separate from the NAND flash storage that constitutes SanDisk's core business. Analysts at InvestorPlace called the sell-off 'analytically indefensible,' and the episode exposes a recurring pattern in how markets process AI efficiency news: traders react to the category label ('memory') rather than the technical substance.
This indiscriminate selling mirrors a broader structural problem in how financial markets metabolize deep-tech research. When Google publishes a paper about KV cache compression, the signal travels through a chain of simplification — research blog to tech press to financial media to trading desk — and at each step, nuance is stripped away. By the time it reaches the algorithmic trading systems and retail investors who drive short-term price action, 'LLM memory compression' becomes 'less memory needed' becomes 'sell all memory stocks.' The result is that SanDisk, trading at 15x earnings with a PEG ratio of 0.01, gets punished for a development in a market segment it barely participates in. For institutional investors with the technical literacy to distinguish HBM from NAND, these mispricings represent exactly the kind of inefficiency that fundamental analysis is designed to exploit.


