
The 242-Point Gap That Rewrites the Image Leaderboard
In ELO-scored benchmarks, a 50-point lead is decisive and a 100-point lead is rare. GPT-Image-2 launched with a +242 lead over Google's Nano Banana 2 in Text-to-Image (1,512 vs 1,270), a +125 lead in Single-Image Edit (1,513), and a +90 lead in Multi-Image Edit (1,464). LM Arena's own commentary — 'No model has dominated Image Arena with margins this wide' — is the story: this isn't GPT-Image-2 narrowly beating the field, it's a model playing a different sport than its peers on the day it shipped.
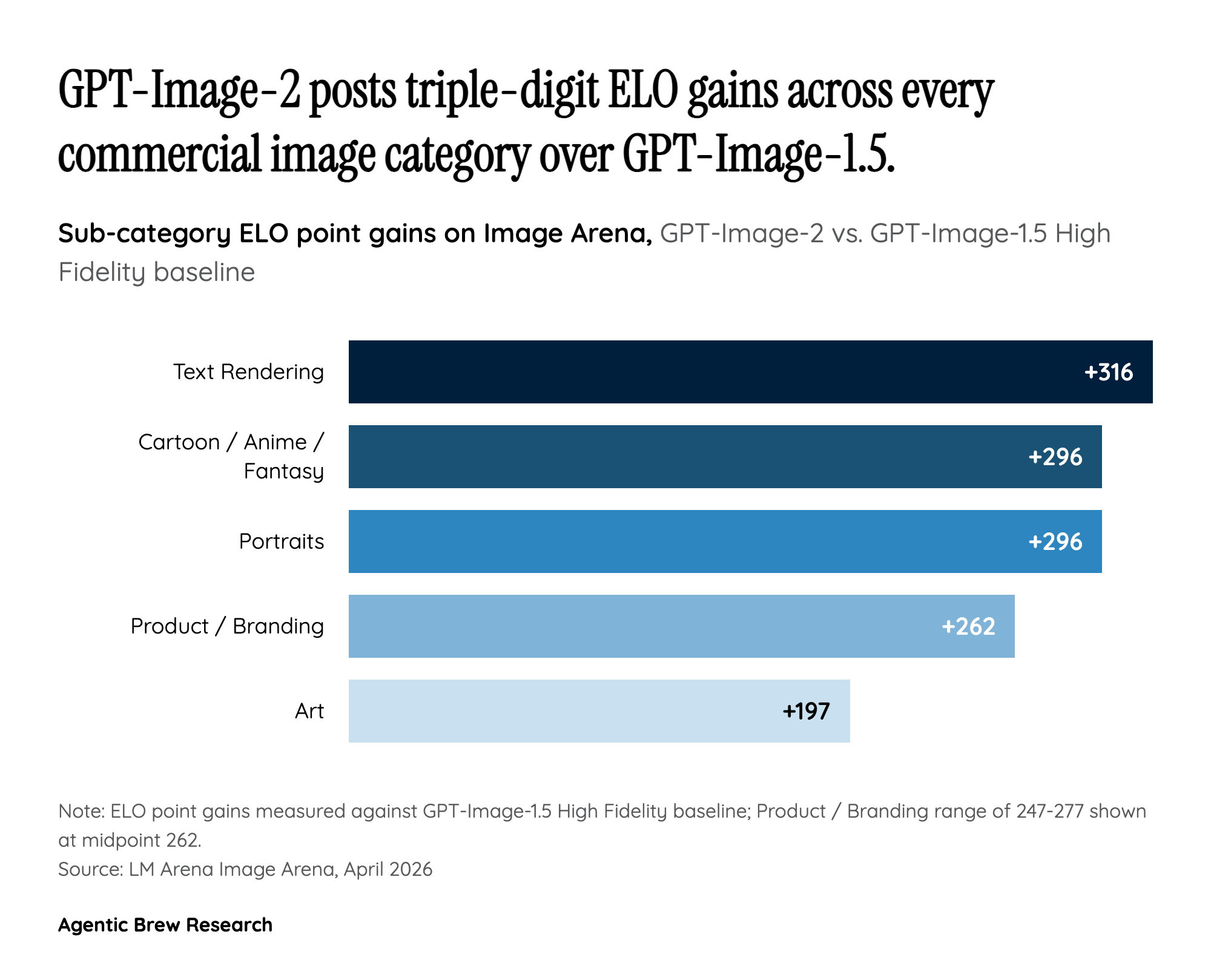
The sub-category breakdown reveals where that gap actually comes from. Over the prior GPT-Image-1.5 High Fidelity baseline, Images 2.0 posted gains of +316 on Text Rendering, +296 on both Cartoon/Anime/Fantasy and Portraits, +247 to +277 on Product and Branding imagery, and +197 on Art. In other words, the largest jumps are in categories where workflow buyers — marketers, designers, publishers — are actually spending money, not the photorealism categories hobbyists argue about on Reddit. The leaderboard sweep isn't a generic 'better model' win; it's a targeted knockout of the commercial use cases Google and Adobe have been competing for.


