The inference inflection: why GPU architecture is newly contestable
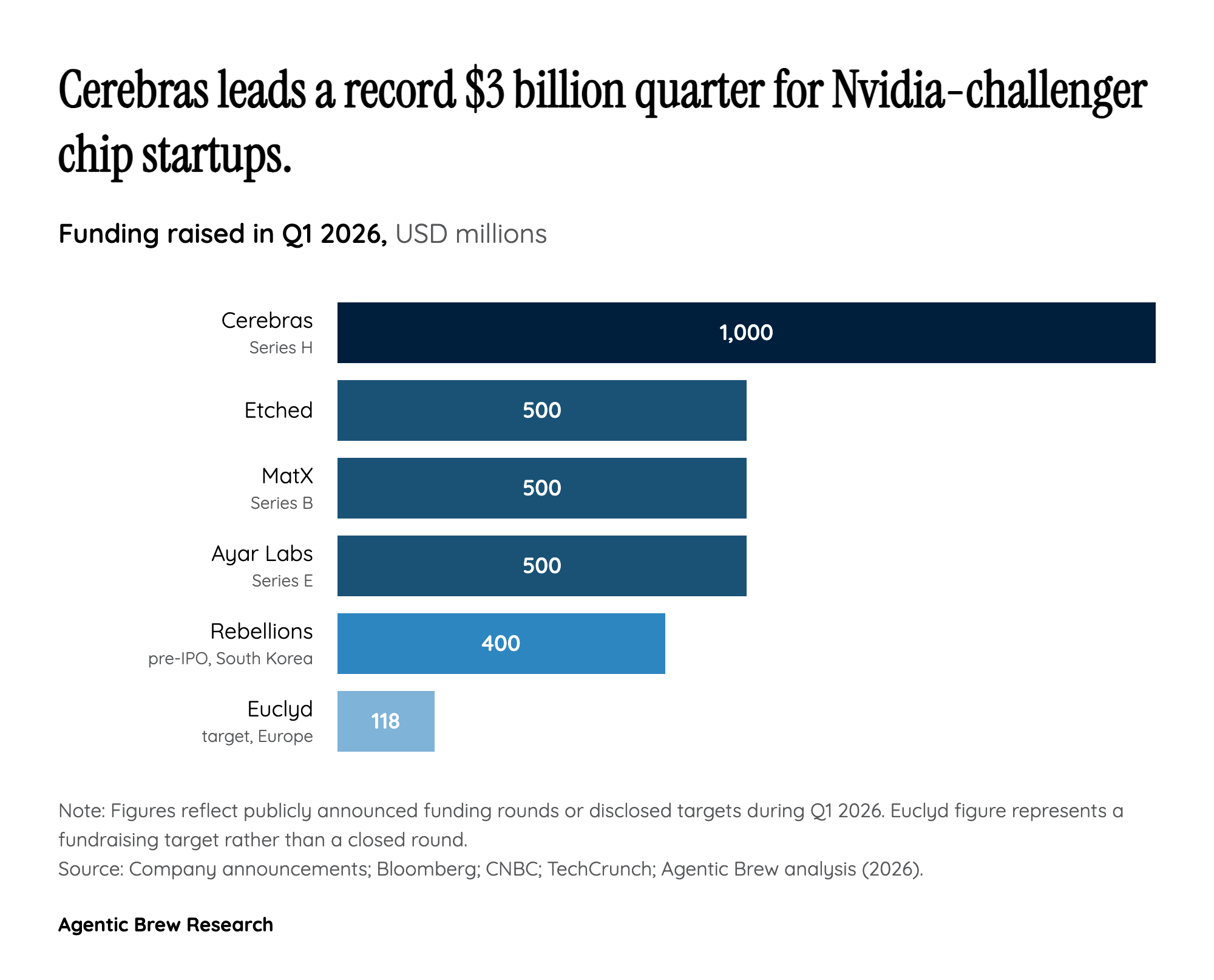
The 2026 funding surge is not a generic bet against Nvidia — it is a targeted bet on inference. Deloitte now pegs inference at roughly two-thirds of AI compute in 2026, up from about one-third in 2023, as frontier labs shift from training new models to serving billions of tokens a day. Nvidia's GPU was architected for massively parallel training — thousands of fungible matrix multiplications — but inference is latency-sensitive, memory-bandwidth bound, and benefits from deterministic dataflow. That is the opening NATO Innovation Fund's Patrick Schneider-Sikorsky names directly when he says "the current GPU architecture was not designed for [inference] in the most significant ways at scale."
Each of the marquee 2026 raises is a different answer to that gap: Etched's Sohu hardcodes the transformer architecture and claims a Llama-70B server runs ~500,000 tokens/sec versus ~23,000 on eight H100s; MatX aims for a 10x LLM performance lift with a cleaner sheet than Nvidia's training-era designs; Cerebras's wafer-scale engine keeps the whole model on-die to eliminate interconnect latency. The thesis is consistent across all four: the most valuable workload in AI has silently migrated to terrain where the incumbent's design choices are liabilities.