
The 'Flash beats Pro' inversion: why a small model now runs the agents
Google's headline trick at I/O 2026 isn't that Gemini 3.5 Flash exists — it's that Flash is now stronger than the prior flagship. DeepMind reports 3.5 Flash outperforming Gemini 3.1 Pro on 'nearly all the benchmarks,' including TerminalBench 2.1 at 76.2%, MCP Atlas at 83.6% and CharXiv reasoning at 84.2% [1]. The reason it matters is structural: in long-horizon agentic workflows you don't make one expensive model call, you make thousands of cheap ones. Tulsee Doshi laid out the new pattern explicitly: '3.5 Pro becomes your orchestrator, your planner, and then it actually can leverage Flash to be the various sub-agents' [2]. So Flash isn't a cheaper consolation prize — it's the worker that fans out under a planner, the unit a developer pays per token to run a hundred copies of in parallel.
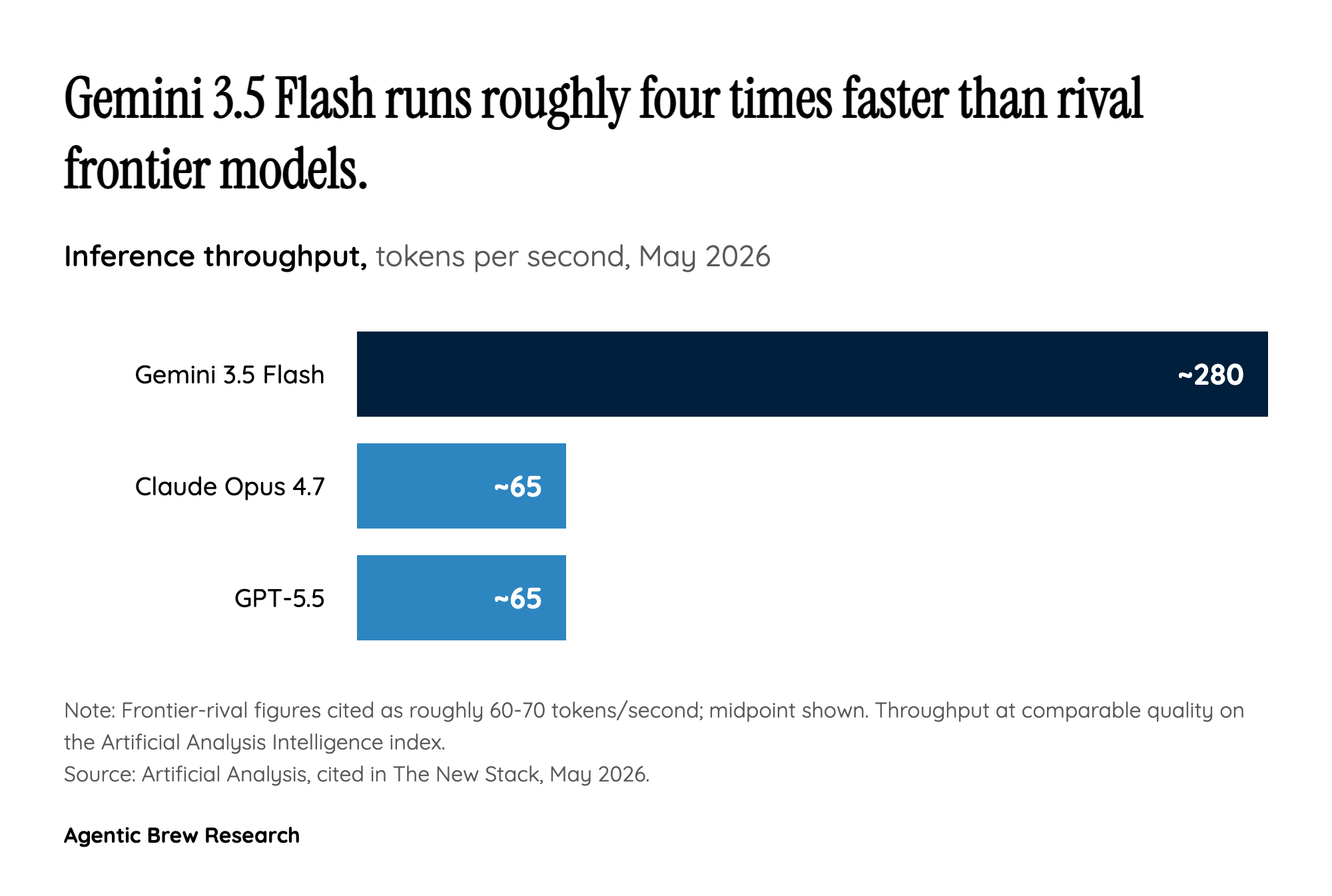
The live demo made the math concrete. Google had agents on Antigravity 2.0 and Gemini 3.5 Flash build a working operating system from scratch: 12 hours of wall time, 93 parallel sub-agents, 15,000+ model requests, 2.6 billion tokens processed, less than $1,000 in API credits. That's not a chatbot demo. It's a budget line item for an entire engineering project. According to Artificial Analysis, Flash runs at around 280 tokens/second versus roughly 60-70 tokens/second for GPT-5.5 and Claude Opus 4.7 [3]. Combine 4x speed with a third of the price and the unit economics for long-horizon agents tilt sharply toward Google — every parallel sub-agent gets cheaper and finishes sooner. The strategic bet behind the relabeling is that the future profitable AI workload is not 'one user one chat' but 'one user a thousand background calls,' and Google is repricing the tier its competitors haven't repriced yet.


