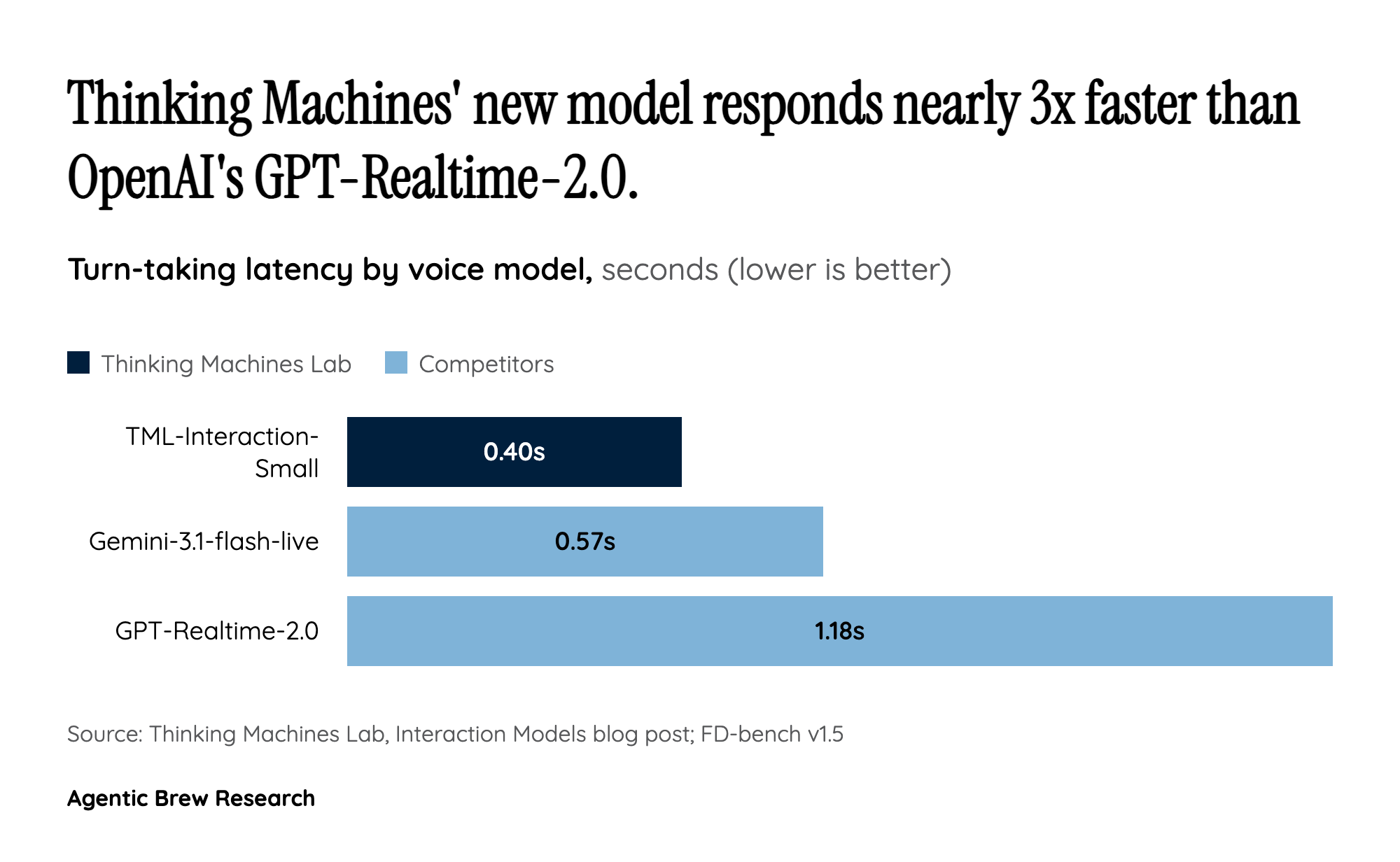
The Pipeline Problem They're Trying to Kill
The central technical argument behind interaction models is not that they're faster — it's that everyone else's voice stack is structurally blind. In today's real-time products like GPT-Realtime and Gemini Live, audio streams in continuously, but the underlying language model never sees the raw signal; it only receives a finalized transcript after a separate ASR layer decides the user has stopped talking [1]. That hand-off is where backchannels, mid-sentence corrections, and visual interjections go to die. The model literally cannot listen while it talks because, at the layer where reasoning happens, it isn't connected to the microphone.
Thinking Machines' fix is to push the multimodal stream all the way into the transformer. Audio enters as dMel signals, video as 40x40 patches, and both are processed through lightweight embedding layers co-trained with the model itself in what the lab calls 'encoder-free early fusion' [2]. The system then runs on 'micro-turns' that interleave 200ms of input ingestion with 200ms of generation, so the same model is simultaneously hearing, watching, and speaking [2]. A separate asynchronous background model handles longer chain-of-thought reasoning and tool calls in parallel, so latency stays low while the system can still 'think.' The bet is that this is the only design where interactivity will continue to work as base models get bigger and slower.