The Slack Pivot: Why the Best Multi-Agent Systems Stopped Forwarding Their Own History
The most consequential pattern emerging from production multi-agent work in 2026 is also the most counterintuitive: the highest-performing long-run agent systems no longer pass message history forward at all. Slack Engineering's April 2026 disclosure of its multi-agent security investigation platform makes this explicit - investigations span hundreds of inference requests and generate megabytes of output, and the team found that naive history-forwarding made later agents incoherent rather than better-informed. Their answer is three specialized context channels: a Director's Journal that supports six entry types (decisions, observations, findings, questions, actions, hypotheses), a Critic's Review, and a Critic's Timeline. Every agent invocation reads from these structured channels; none reads raw transcripts.
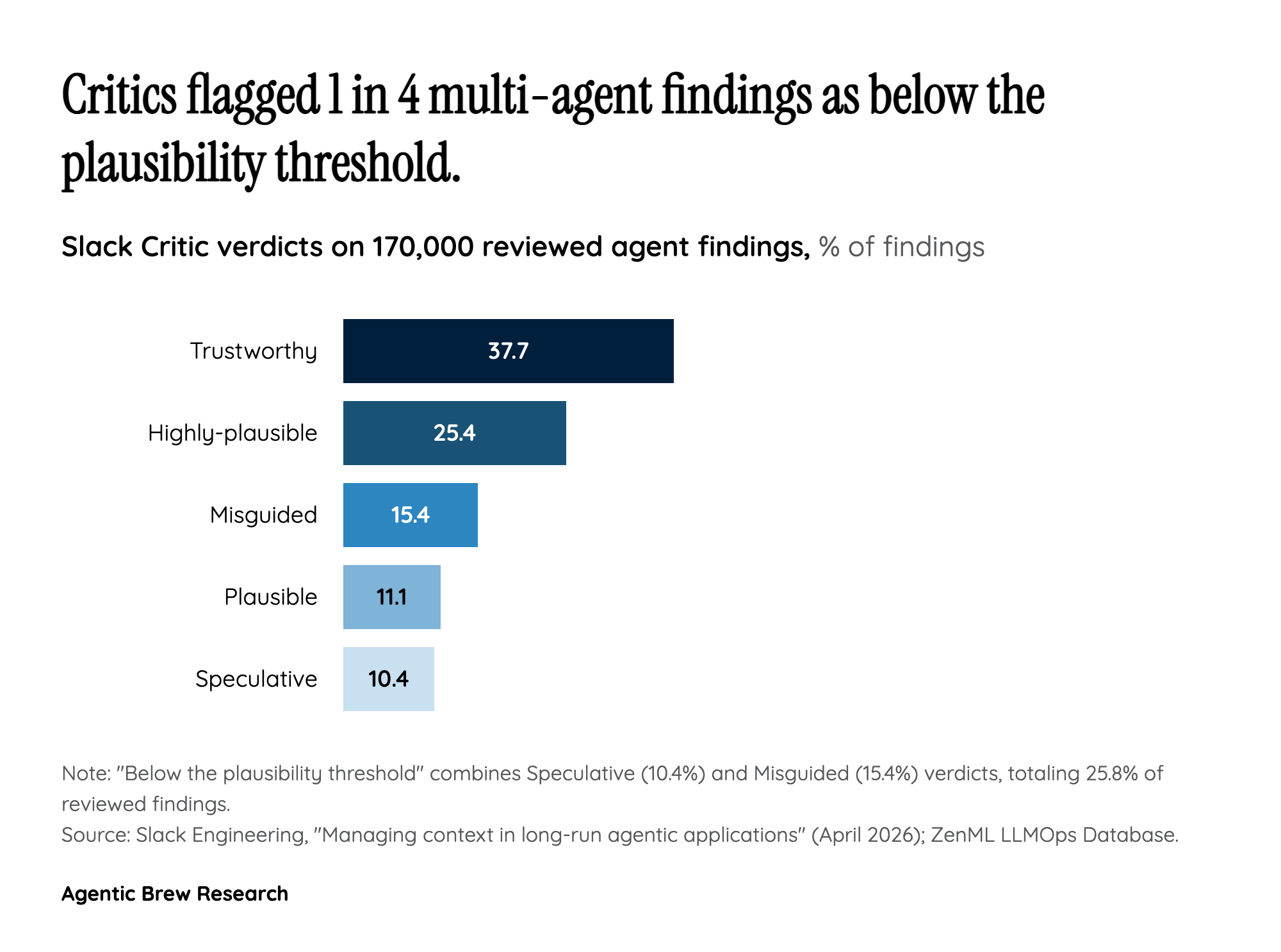
The deeper claim is architectural. The Director's Journal isn't a log - it is the orchestrator's reasoning rendered as structured working memory, with phase, round, timestamp, priority, and citations attached to every entry. Slack's own framing is that 'the Journal allows the Director to lead the investigation towards a conclusion, to observe and measure its progress.' The Critic, meanwhile, processed 170,000 reviewed findings broken down as 37.7% Trustworthy, 25.4% Highly-plausible, 11.1% Plausible, 10.4% Speculative, and 15.4% Misguided - a quantified epistemic filter that prevents downstream agents from compounding low-quality intermediate beliefs. The lesson many teams are now drawing: multi-agent coherence is a context-engineering problem, not a model-capability problem, and the unit of design is the channel, not the prompt.