The mechanism: post-training did the heavy lifting
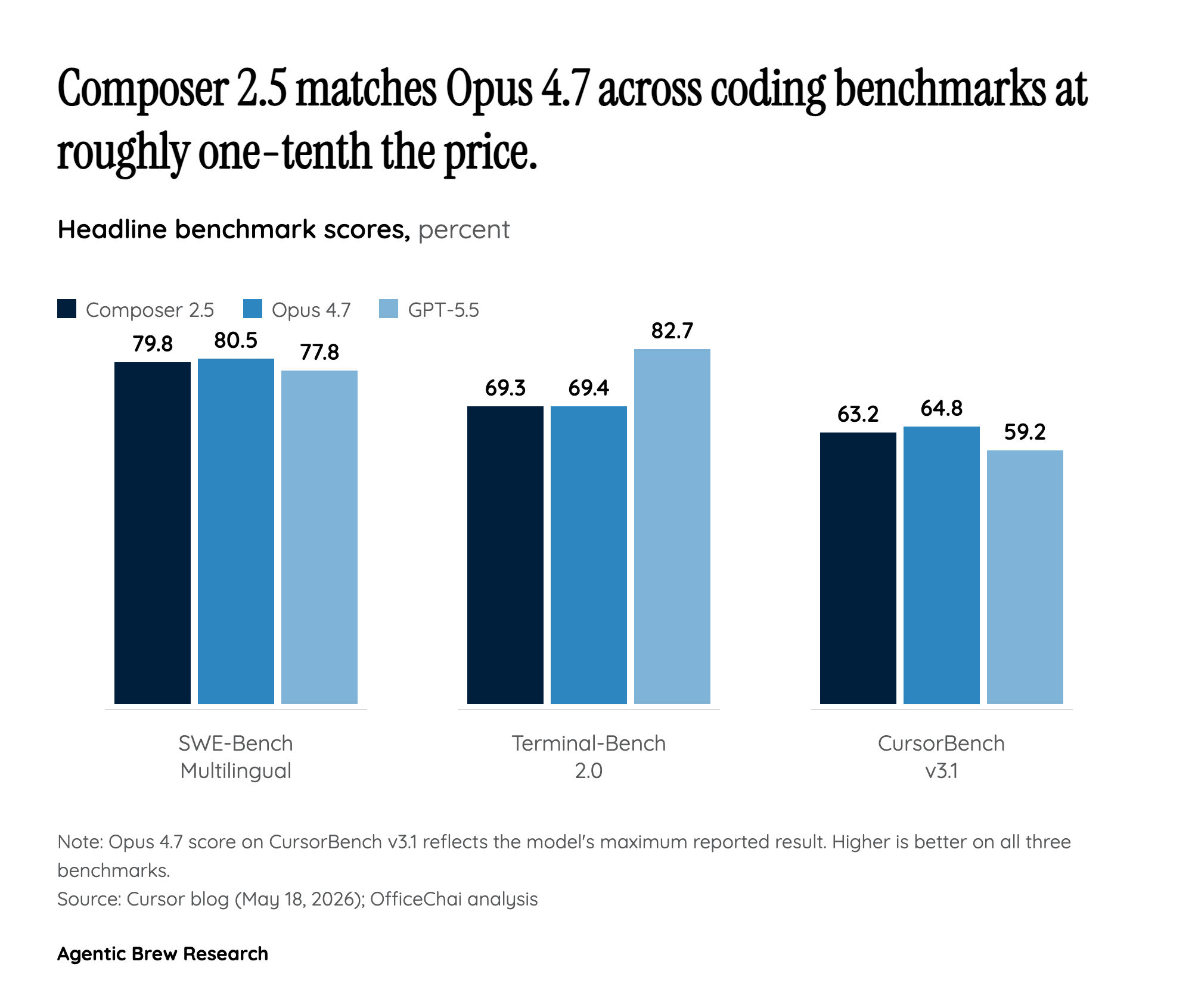
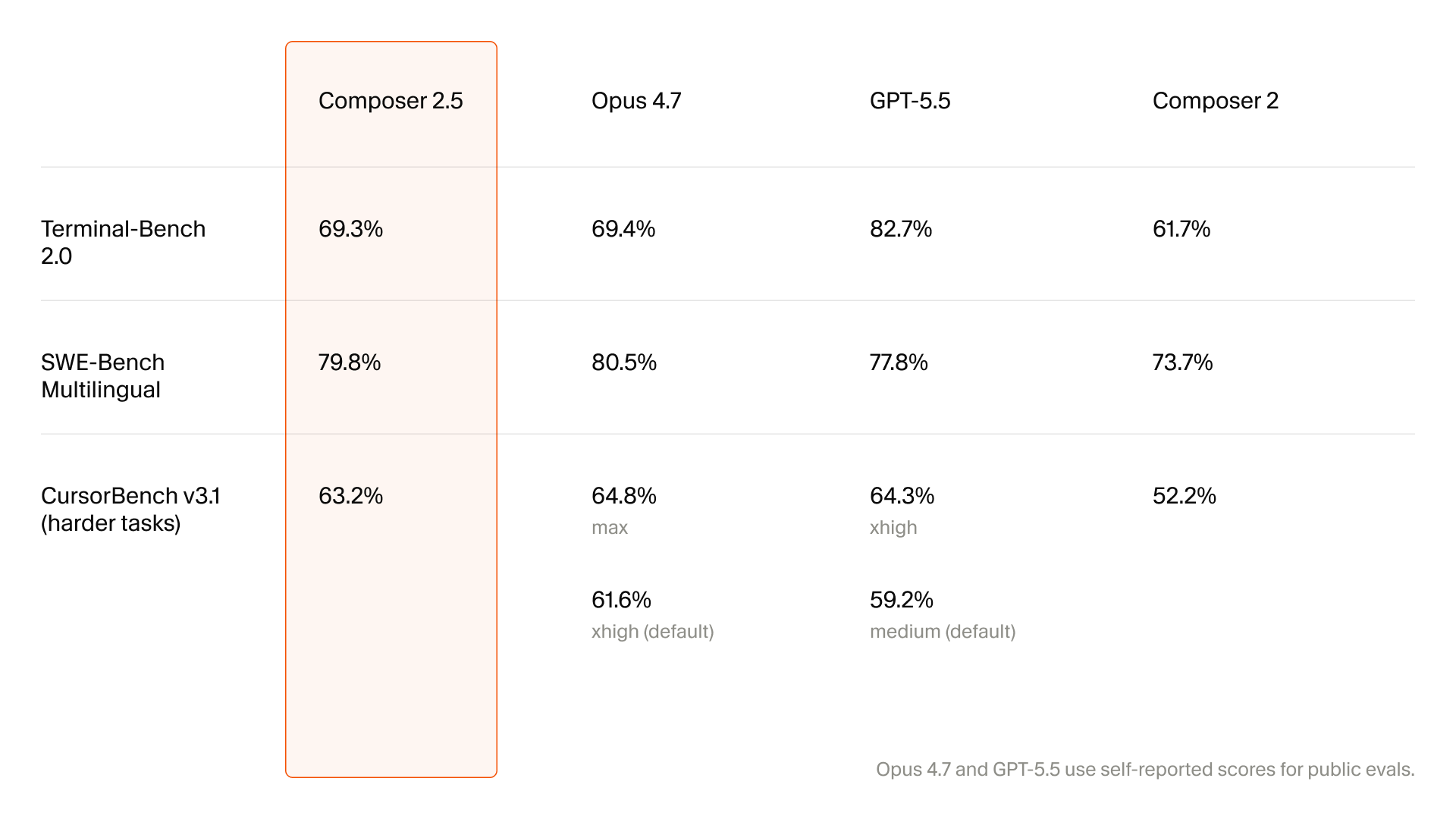
Composer 2.5 didn't get a new brain — it got a much better tutor. The model still rides on Moonshot's open-source Kimi K2.5 checkpoint, the same base Cursor used for Composer 2 [3]. What changed is how Cursor spent its compute on top: roughly 85% of total compute went into Cursor's own post-training and reinforcement learning, including 25x more synthetic tasks than Composer 2 [1][6]. The signature trick is what Cursor calls Targeted RL with Textual Feedback: instead of grading an entire multi-step coding rollout against a single end-of-episode reward, the system inserts localized hints precisely at the point where the model errs, sharpening credit assignment over rollouts that span hundreds of thousands of tokens [1].
Cursor also leans on a 'feature deletion' technique where the agent is forced to reimplement removed code against an existing test suite — a synthetic curriculum that pushes the model toward sustained, verifiable work rather than one-shot completions [1][5]. The whole stack runs through a Sharded Muon optimizer that hits a 0.2-second optimizer step time on a 1T-parameter model, which is what makes throwing 25x more synthetic curriculum at the model economically tractable in the first place [1][6].

![[This is Incredible] Cursor's New "Composer 2.5" Model: Has It Evolved to Opus-Level? Massive Per...](https://img.youtube.com/vi/ukEmEnfK2BQ/mqdefault.jpg)