Why This Matters
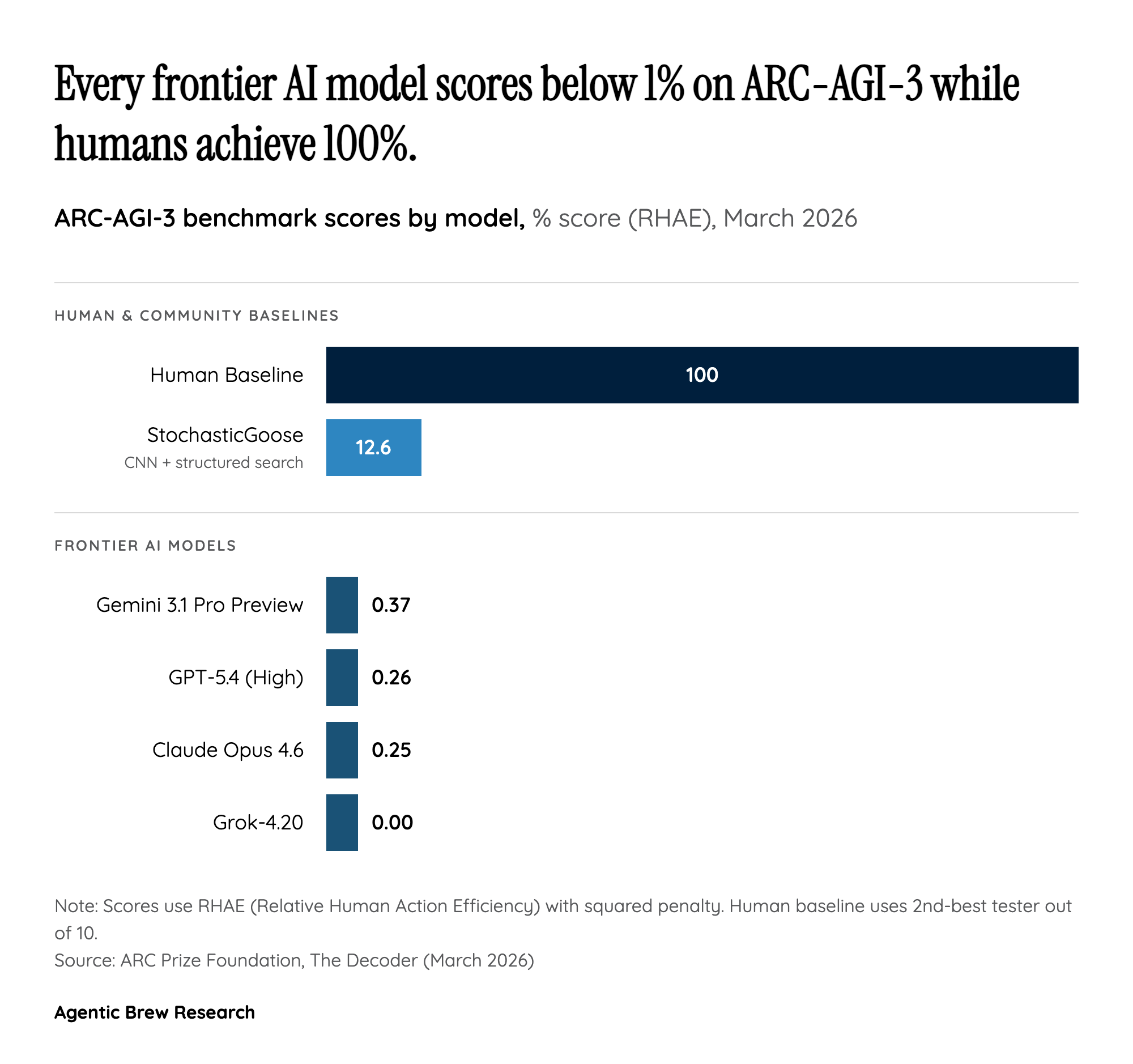
ARC-AGI-3 arrives at a moment when the AI industry faces a credibility crisis in benchmarking. Over the past two years, frontier models have rapidly saturated one benchmark after another — from MMLU to HumanEval to ARC-AGI-1 itself. Each time a benchmark is conquered, it is quickly dismissed as insufficiently challenging, and the goalposts shift. ARC-AGI-3 represents the most deliberate attempt yet to create a benchmark that cannot be gamed through memorization, scale, or clever prompting. The fact that every frontier model scores below 1% while untrained humans achieve 100% is not merely an embarrassing number — it is a structural claim about what current AI systems fundamentally cannot do.
The stakes extend well beyond academic measurement. As Mike Knoop reports, frontier labs are paying far more attention to this version than its predecessors. The social response on X.com confirms the benchmark has captured the AI community's attention: the official @arcprize announcement — framing ARC-AGI-3 as the test of "how [models] learn" rather than "what models already know" — generated over 4,300 engagements (3,500 likes, 691 retweets, 188 replies) within the first day. Meanwhile, @scaling01's post breaking down individual model scores (Gemini 3.1 Pro at 0.37%, GPT-5.4 at 0.26%, Opus 4.6 at 0.25%, Grok 4.2 at 0%) attracted over 3,300 engagements, indicating intense public interest in the concrete performance gap. This level of social signal, combined with the $2 million prize pool and open-source requirement, suggests ARC-AGI-3 has achieved something rare: genuine buy-in from both the research community and the organizations whose systems it critiques.