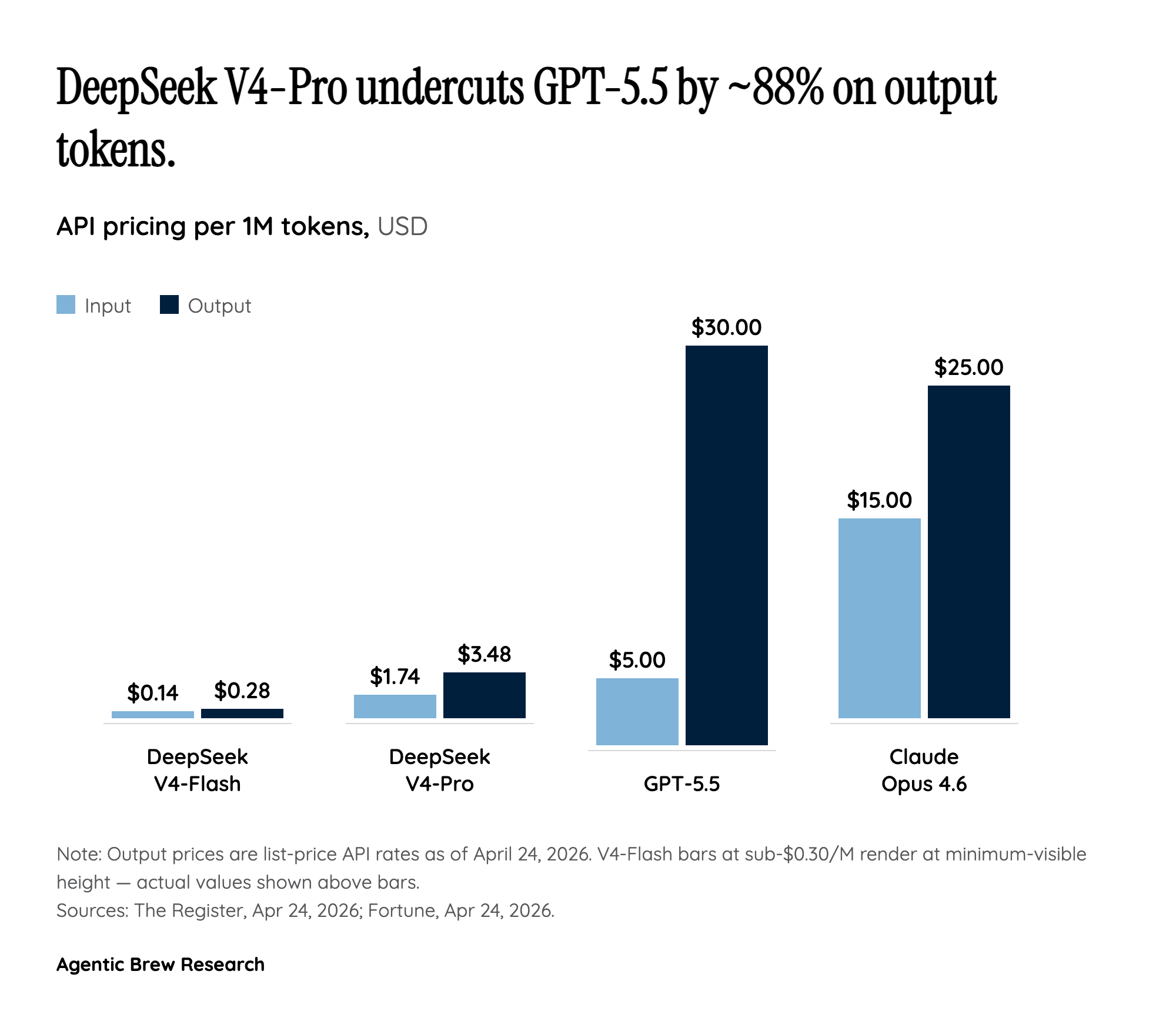
The Real Headline Isn't the Model — It's the Stack
Strip away the benchmark numbers and what V4 actually proves is structural: for the first time, a frontier-class open-weight model launched with same-day inference support on Huawei Ascend NPUs and Cambricon accelerators, with the integration code open-sourced to GitHub. That is a different category of event than 'another Chinese model release'. R1 in January 2025 made Silicon Valley nervous about Chinese training efficiency; V4 makes Silicon Valley nervous about something harder to fix — a Chinese end-to-end stack from chip to compiler to model that ships on the same calendar day as the model itself.
This is the scenario Jensen Huang named out loud: 'the day that DeepSeek comes out on Huawei first, that is a horrible outcome' for the United States. April 24 was not literally that day — Liu Zhiyuan of Tsinghua notes V4's main pre-training was likely still done on NVIDIA hardware, and only parts of the training were adapted to Chinese chips. But the inference path, where the dollars actually live for a deployed model, is now demonstrably non-NVIDIA-feasible at flagship quality. Huatai Securities' brokerage desk read it as a direct catalyst for domestic-chip adoption in 2026; the SMIC stock jump of roughly 10% the same day suggests the equity market agrees. The geopolitical signal is the lead, not the lagging indicator.