The mechanism: rack-scale inference, not another server CPU
What changed since Qualcomm's 2018 retreat is the architecture of the bet. Centriq tried to win in general-purpose Arm servers against an x86 fortress; the new entry is purpose-built for AI inference, sold as a rack rather than a chip. The AI200 packs 768 GB of LPDDR per card, draws 160 kW per rack, uses direct liquid cooling, and scales up to 72 chips per system, with the AI250 promising 'more than 10x higher effective memory bandwidth' via near-memory computing in 2027. The pitch is that inference economics are a memory-bandwidth and TCO problem more than a peak-FLOPS problem — exactly the workload profile where Qualcomm's mobile-derived Hexagon NPUs and post-NUVIA CPU IP are most defensible.
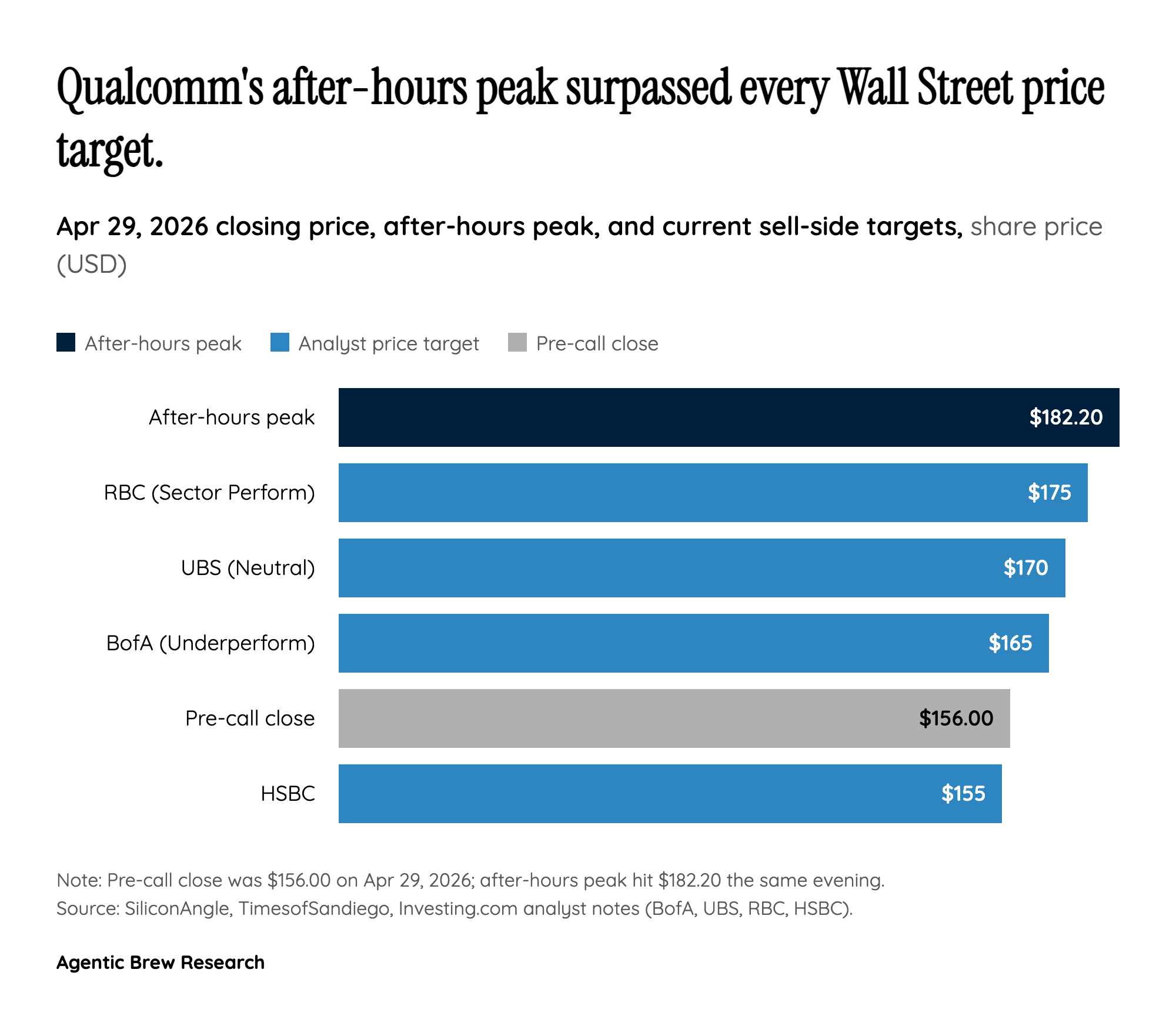
The hyperscaler engagement layered on top of this is a different shape of business than selling catalog parts. CEO Cristiano Amon framed it as 'a leading hyperscaler custom silicon engagement' with multi-generation cadence, meaning Qualcomm is doing semi-custom work — closer to the Broadcom/Marvell model than to Nvidia's merchant GPU model. That matters because custom silicon programs tend to lock in unit economics and roadmaps for years once the first tape-out lands, but they also concentrate revenue on a single customer and a single workload. December 2026 first shipments puts Qualcomm in market roughly a year behind its own AI200 launch and well behind Nvidia's Blackwell rack cadence — which is the gap the equity story is now valued against.