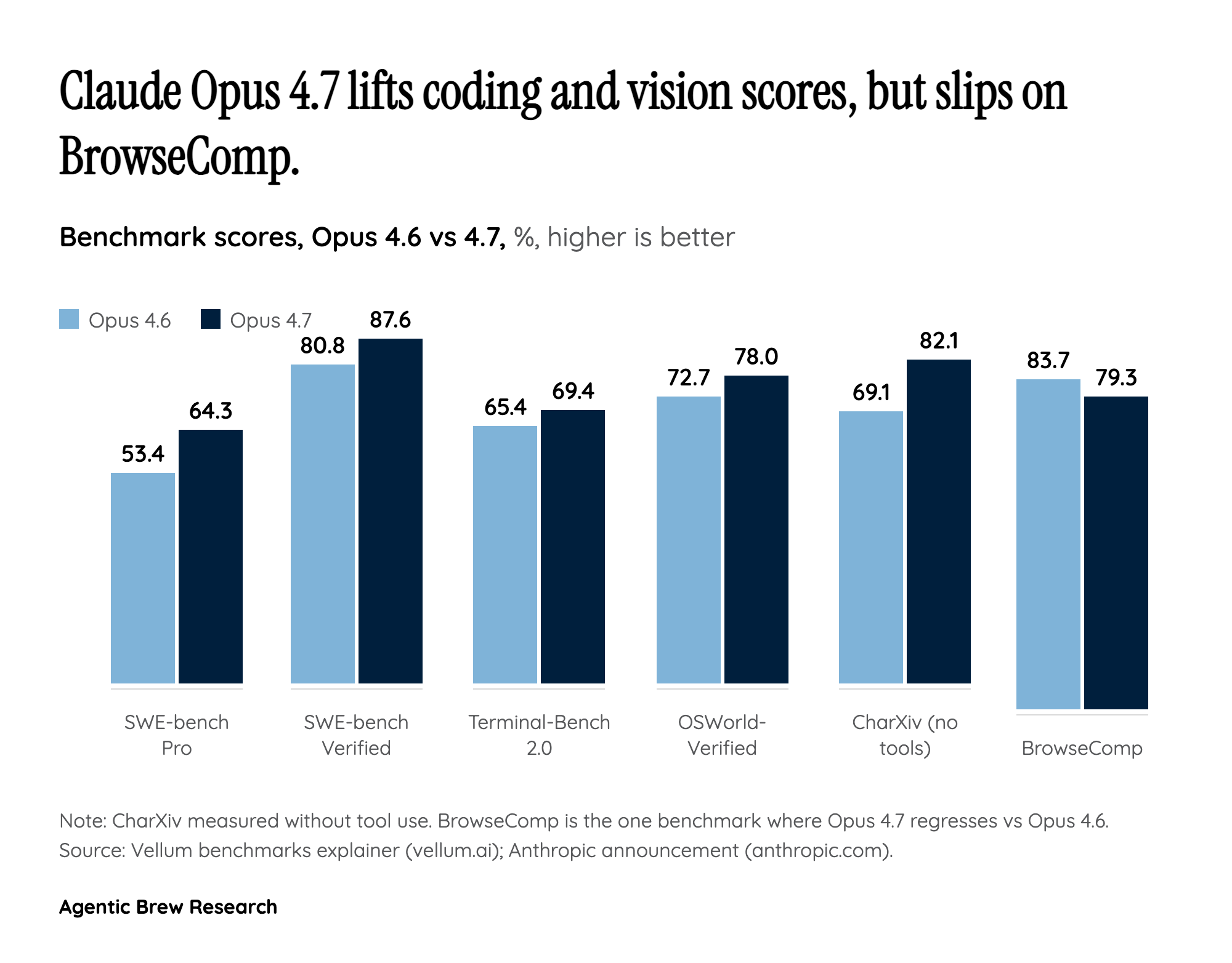
The Mythos Shadow
The single strangest thing about Claude Opus 4.7 is what Anthropic chose not to ship. In the same materials that call 4.7 its most powerful generally available model, the company acknowledges an even more capable system — Claude Mythos Preview — that remains locked behind Project Glasswing, distributed to only about 40 vetted enterprise and government partners. The stated reason is safety: Mythos can autonomously discover and exploit zero-day vulnerabilities, a capability Anthropic is not willing to put on a public rate card.
That framing reshapes how to read 4.7. It is not simply the next iteration on a linear curve; it is a deliberately constrained sibling of a model the company believes is too dangerous to release broadly. Anthropic says it reduced cyber capabilities during training and added automatic detection and blocking of high-risk cybersecurity requests, pairing that with a new Cyber Verification Program for researchers who need access to the sharper edges. The result is a product that is explicitly less than what Anthropic could ship — a posture that will either look prudent or self-sabotaging depending on whether rival labs feel bound by the same line.