.jpg)
From Selling Shovels to Selling the Whole Stack
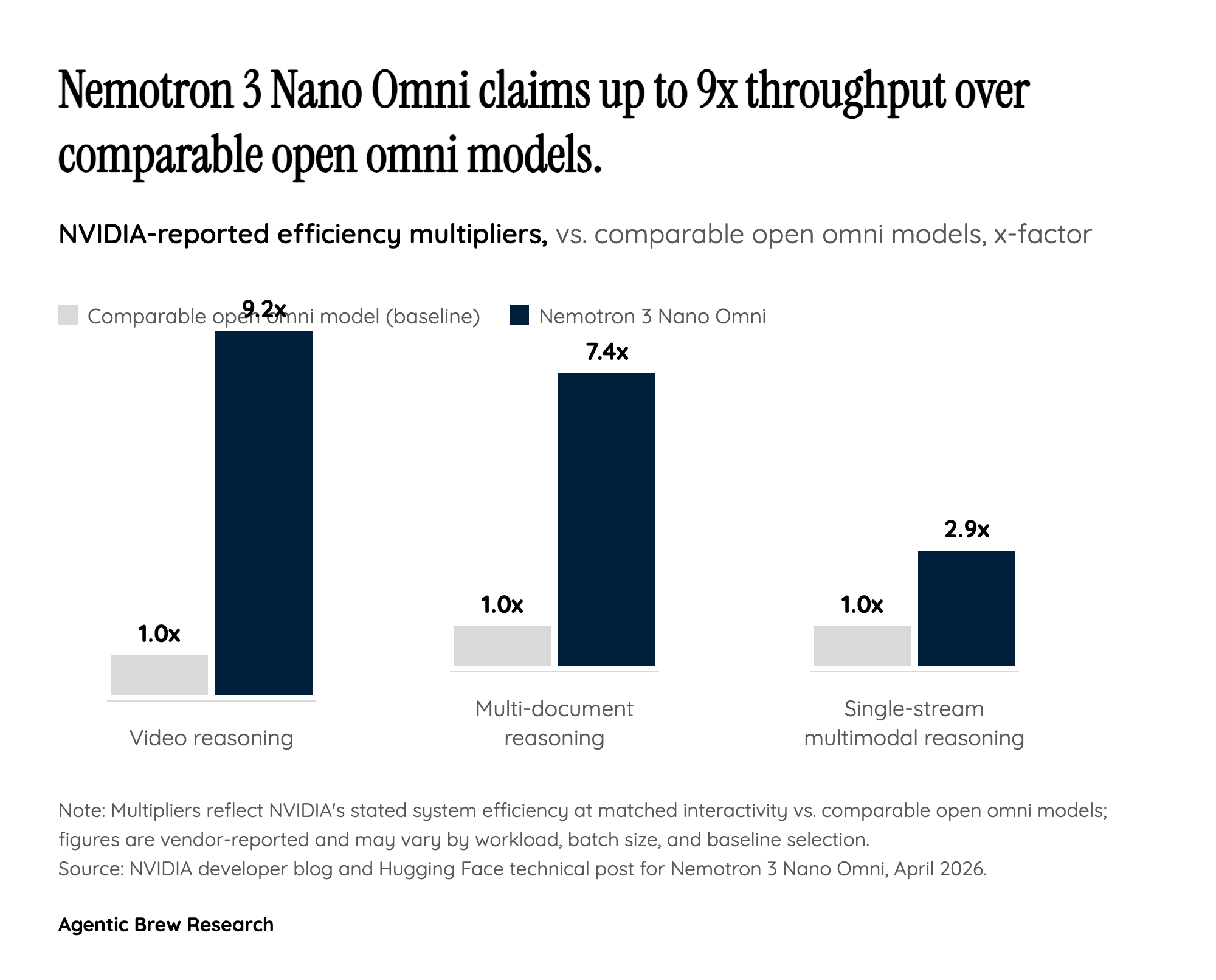
For most of the generative-AI cycle, NVIDIA's pitch has been simple: every model gets trained and served on our chips, so we win regardless of who builds the AGI. Nemotron 3 Nano Omni is the clearest signal yet that the company no longer believes that posture is sufficient. By shipping an open-weight 30B-A3B multimodal model with a stated goal of powering enterprise computer-use agents, document intelligence, and factory-floor inspection, NVIDIA is moving from infrastructure provider to model provider — competing, however gently, with the very labs that buy its GPUs.
The strategic logic shows up clearly in the launch's named partners. Foxconn for manufacturing, Palantir for government and operations, H Company for computer-use agents, Eka Care for healthcare in India — these are exactly the kinds of customers who buy enterprise platforms, not single API tokens. Futurum Group's David Nicholson reads the move as a hedge against hyperscaler pressure on NVIDIA's hardware margins, suggesting the company is positioning open Nemotron weights as a way to keep enterprises building on NVIDIA's stack end-to-end even as Amazon, Google, and Microsoft push their own silicon. On Reddit, one r/ArtificialIntelligence post framed it bluntly: NVIDIA is 'no longer just selling the shovels.' Whether that becomes a durable second franchise or just a defensive moat is the open question Nicholson himself raises — is this a hyperscaler play, an SMB play, or both?